FSDnoisy18k
In this site you can find a detailed description of FSDnoisy18k with emphasis on the label noise characteristics, as well as some basic dataset stats. You can also download FSDnoisy18k.
Authors
The following people contributed to FSDnoisy18k:
Eduardo Fonseca, Mercedes Collado, Manoj Plakal, Daniel P. W. Ellis, Frederic Font, Xavier Favory, and Xavier Serra
Data curators
Eduardo Fonseca and Mercedes Collado
Contact
You are welcome to contact Eduardo Fonseca should you have any questions at eduardo.fonseca@upf.edu.
Citation
If you use this dataset or part of it, please cite the following ICASSP 2019 paper:
Eduardo Fonseca, Manoj Plakal, Daniel P. W. Ellis, Frederic Font, Xavier Favory, and Xavier Serra, “Learning Sound Event Classifiers from Web Audio with Noisy Labels”, arXiv preprint arXiv:1901.01189, 2019
You can also consider citing our ISMIR 2017 paper that describes the Freesound Annotator, which was used to gather the manual annotations included in FSDnoisy18k.
Eduardo Fonseca, Jordi Pons, Xavier Favory, Frederic Font, Dmitry Bogdanov, Andres Ferraro, Sergio Oramas, Alastair Porter, and Xavier Serra, “Freesound Datasets: A Platform for the Creation of Open Audio Datasets”, In Proceedings of the 18th International Society for Music Information Retrieval Conference, Suzhou, China, 2017
FSDnoisy18k description
The following description complements (but not entirely substitutes) the description provided in Section 2 of our ICASSP 2019 paper. More specifically, this description focuses on the label noise characterization of the dataset. Details about the annotation procedure and the dataset creation process are described in our paper. Hence, for a complete picture of FSDnoisy18k please also check the Section 2 of such paper.
FSDnoisy18k is an audio dataset collected with the aim of fostering the investigation of label noise in sound event classification. It contains 42.5 hours of audio across 20 sound classes, including a small amount of manually-labeled data and a larger quantity of real-world noisy data.
The source of audio content is Freesound—a sound sharing site created an maintained by the Music Technology Group hosting over 400,000 clips uploaded by its community of users, who additionally provide some basic metadata (e.g., tags, and title). More information about the technical aspects of Freesound can be found in [14, 15].
The 20 classes of FSDnoisy18k are drawn from the AudioSet Ontology and are selected based on data availability as well as on their suitability to allow the study of label noise. For example:
- some classes are selected because the tags typically used to describe them can also be used for other audio material. Hence when the content for these classes is retrieved by the typical user-provided tags (as is our case), it is likely to feature a certain amount of label noise. Some examples of these classes are: Bass guitar, Crash Cymbal, Engine, Fire, …
- some classes are chosen because their clips are typically outdoor field-recordings, where several sound sources are expected to be present (although it is likely that only the most predominant(s) are indeed tagged); for example: Rain, Fireworks, Slam, Fire, …
- some pairs of classes are chosen due to their relation. For example, Slam and Squeak are often the outcome of one physical phenomenon (cloosing a door), hence they may co-occur in a clip despite sometimes only one may be tagged. Another example is Wind and Rain.
Check section Label noise characteristics for some specific examples, along with the explanation of the label noise types they pose.
They are listed in the next Table, along with the number of audio clips per class (split in different data subsets that are defined in section FSDnoisy18k basic characteristics). Every numeric entry in the next table reads: number of clips / duration in minutes (rounded). For instance, the Acoustic guitar class has 102 audio clips in the clean subset of the train set, and the total duration of these clips is roughly 11 minutes.
| Class | train - clean | train - noisy | test |
|---|---|---|---|
| 1 - Acoustic guitar | 102 / 11 | 896 / 124 | 42 / 4 |
| 2 - Bass guitar | 106 / 11 | 1000 / 142 | 71 / 5 |
| 3 - Clapping | 82 / 3 | 846 / 104 | 57 / 4 |
| 4 - Coin (dropping) | 170 / 7 | 589 / 57 | 70 / 4 |
| 5 - Crash cymbal | 76 / 6 | 1000 / 105 | 52 / 4 |
| 6 - Dishes, pots, and pans | 83 / 4 | 764 / 105 | 56 / 3 |
| 7 - Engine | 137 / 20 | 995 / 172 | 49 / 10 |
| 8 - Fart | 71 / 2 | 687 / 43 | 30 / 1 |
| 9 - Fire | 81 / 7 | 751 / 132 | 54 / 5 |
| 10 - Fireworks | 51 / 4 | 331 / 55 | 30 / 3 |
| 11 - Glass | 157 / 12 | 998 / 123 | 54 / 3 |
| 12 - Hi-hat | 81 / 3 | 911 / 45 | 38 / 1 |
| 13 - Piano | 96 / 12 | 1000 / 174 | 72 / 8 |
| 14 - Rain | 65 / 9 | 443 / 117 | 36 / 6 |
| 15 - Slam | 78 / 3 | 1000 / 129 | 53 / 2 |
| 16 - Squeak | 67 / 4 | 931 / 116 | 31 / 2 |
| 17 - Tearing | 62 / 4 | 428 / 54 | 30 / 3 |
| 18 - Walk, footsteps | 77 / 7 | 1000 / 206 | 52 / 6 |
| 19 - Wind | 64 / 7 | 993 / 276 | 40 / 5 |
| 20 - Writing | 66 / 8 | 250 / 48 | 30 / 4 |
Part of the content of FSDnoisy18k overlaps with that of FSD, a work-in-progress, large-scale dataset built of Freesound content organized with the AudioSet Ontology. More specifically, some of the clean data in FSDnoisy18k are also being considered for FSD, whereas some of the content of FSDnoisy18k is incorrectly labeled and therefore it is not considered in FSD. For more information about FSD please check our ISMIR 2017 paper. You can also visit the Freesound Annotator, which is a platform for the collaborative creation of open audio datasets that was used for the creation of FSDnoisy18k (and is being used for the creation of FSD).
We defined a clean portion of the dataset consisting of correct and complete labels. The remaining portion is referred to as the noisy portion. Each clip in the dataset has a single ground truth label (singly-labeled data).
The clean portion of the data consists of audio clips whose labels are rated as present in the clip and predominant (almost all with full inter-annotator agreement), meaning that the label is correct and, in most cases, there is no additional acoustic material other than the labeled class. A few clips may contain some additional sound events, but they occur in the background and do not belong to any of the 20 target classes. This is more common for some classes that rarely occur alone, e.g., “Fire”, “Glass”, “Wind” or “Walk, footsteps”.
The noisy portion of the data consists of audio clips that received no human validation. In this case, they are categorized on the basis of the user-provided tags in Freesound. Hence, the noisy portion features a certain amount of label noise.
Code
We’ve released the code for our ICASSP 2019 paper at https://github.com/edufonseca/icassp19. The framework comprises all the basic stages: feature extraction, training, inference and evaluation. After loading the FSDnoisy18k dataset, log-mel energies are computed and a CNN baseline is trained and evaluated. The code also allows to test four noise-robust loss functions. Please check our paper for more details.
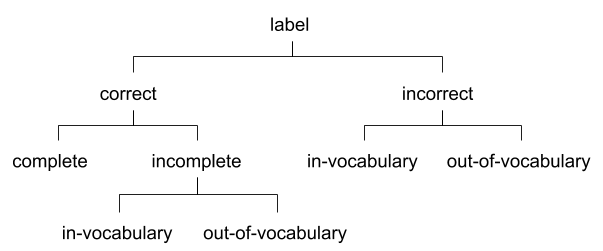
Label noise characteristics
FSDnoisy18k features real label noise that is representative of audio data retrieved from the web, particularly from Freesound. We propose a taxonomy of label noise for singly-labeled data following an empirical approach. The taxonomy is shown in Fig. 1 and includes the noise types identified through manual inspection of a per-class, random, 15% of the noisy portion of FSDnoisy18k.
Its concepts are explained next with the main use cases found in FSDnoisy18k. We distinguish between additional events that are already part of our target class set (“in-vocabulary” or IV), or are not covered by those classes (“out-of-vocabulary” or OOV). Given an observed label that is incorrect or incomplete, the true or missing label can then be further classified as IV or OOV.
 |
|---|
| Fig 1. Taxonomy of label noise based on the analysis of the noisy data in FSDnoisy18k. |
Some classes are prone to include incorrect labels when the clips are retrieved only on the basis of their existing user-provided tags, e.g., “Bass guitar”, “Crash cymbal”, or “Engine”; typically, the true label does not belong to the list of considered classes (incorrect/OOV). Other classes are prone to have audio clips with acoustic material that is additional to the provided (and correct) label, e.g., “Rain”, “Fireworks” or “Slam”, and, again, the missing label usually does not belong to the list of considered classes (incomplete/OOV). Finally, a few classes are related to each other. It can happen that one class contains clips that actually belong to another class in the dataset, e.g. “Wind” and “Rain” (incorrect/IV). Alternatively, two sound classes can co-occur in an audio clip, e.g. “Slam” and “Squeak”, despite only a single label is available (in-complete/IV). For completeness, correct and complete labels mean no label noise, i.e., clean data.
In addition to the aforementioned noise types, two more types arise in the context of web audio and Freesound in particular. First, determining whether a sound class is present in an audio clip can be subjective, even for an expert. This happens with human imitations or heavily processed sounds (e.g., with sound effects). We refer to these clips as ambiguous as it is unclear whether the label is correct or not. The second noise type relates to i) the variable clip lengths and ii) the weak nature of the clip-level labels. A naive but common way of processing variable-length clips is to split them into several fixed-length patches, each inheriting the clip-level label (called false strong labeling in [20]). This can generate false positives if the label is not active in a given patch. This type of label noise is conceptually similar to the label density noise of [10].
The analysis of the noisy data revealed that roughly 40% of the analyzed labels are correct and complete, whereas 60% of the labels show some type of label noise, whose distribution is listed in the next Table.
| Label noise type | Percentage |
|---|---|
| Overall | 60% |
| Incorrect/OOV | 38% |
| Incomplete/OOV | 10% |
| Incorrect/IV | 6% |
| Incomplete/IV | 5% |
| Ambiguous labels | 1% |
The most frequent types of label noise correspond to out-of-vocabulary (OOV) problems, either in the form of incorrect labels (that generate false positives) or incomplete labels (which generate false negatives). Furthermore, we have observed that a few clips within the incorrect/OOV category are incorrectly labeled according to the semantic meaning of the class, and yet they are relatively similar (in terms of their acoustics) to the true label. For example, in “Clapping” there is a certain amount of applause sounds and claps generated by drum machines. We estimate that ≈10% of the clips analyzed shows this phenomenon, although we recognize it is highly subjective. This ≈10% is included in the 38% of incorrect/OOV labels. The degree of total label noise per-class ranges from 20% to 80% roughly.
The label density noise is only relevant in few classes, especially “Slam”, and to a lesser extent “Fireworks” and “Fire”. This type of noise was quantified by counting the audio clips that present at least one segment of 2s (or more) where the observed label is not present (2s is the patch length used for processing the variable length clips in the baseline system).
To facilitate per-class analysis, a per-class description of the label noise is included in the next Table. The Table was compiled as follows. For every class, a random 15% of the noisy portion was manually inspected. During this process, the label noise problems according to the taxonomy of Fig. 1 were identified and quantified. We show here the % of audio clips presenting each noise problem. The first six columns of the Table represent mutually exclusive concepts and therefore they should sum 100%. However, we only list the most relevant noise problems (and omit the marginal ones, marking them with a -). The seventh column (label density noise (LDN)) is an additional type of label noise that can co-exist with the previous ones. Again, it is expressed as the % of audio clips presenting this phenomenon (see our ICASSP 2019 paper for further details). Please note that the % listed are just an estimation of the actual label noise present in FSDnoisy18k (based on an analysis of only 15% of the noisy portion). Therefore, the numbers of the next Table should be taken as a rough characterization of the label noise problematic, and not as a detailed one.
| Class | C&C | Incorrect/OOV | Incomplete/OOV | Incorrect/IV | Incomplete/IV | Ambiguous | LDN |
|---|---|---|---|---|---|---|---|
| Acoustic guitar | 84% | 9% | - | - | - | - | - |
| Bass guitar | 20% | 74%* | - | - | 3% | - | - |
| Clapping | 26% | 58%* | 9% | - | - | - | 4% |
| Coin (dropping) | 32% | 49%* | 9% | - | 7% | - | 6% |
| Crash cymbal | 13% | 74%* | - | 12% | - | - | - |
| Dishes, pots, and pans | 44% | 41%* | - | 9% | - | - | 3% |
| Engine | 30% | 58% | 7% | - | - | - | 3% |
| Fart | 74% | 16% | 7% | - | - | - | 4% |
| Fire | 16% | 51% | 24% | - | - | - | 14% |
| Fireworks | 56% | 6% | 28% | - | - | - | 18% |
| Glass | 53% | 36% | - | 6% | - | - | 4% |
| Hi-hat | 74% | 14% | - | - | - | 8% | - |
| Piano | 36% | 53%* | - | 7% | - | - | - |
| Rain | 29% | 26% | 34% | - | 8% | - | - |
| Slam | 28% | 19% | 27% | 10% | 14% | - | 34% |
| Squeak | 56% | 16% | 4% | 4% | 17% | - | 10% |
| Tearing | 46% | 42%* | 12% | - | - | - | 12% |
| Walk, footsteps | 35% | 28% | 18% | - | 10% | - | 4% |
| Wind | 20% | 37%* | 8% | 26% | 6% | - | 4% |
| Writing | 61% | 15% | 10% | - | - | 8% | 10% |
LEGEND:
- C&C means correct and complete.
- LDN means label density noise (see our ICASSP 2019 paper for further details).
- *These categories have clips within the Incorrect/OOV noise problem that are incorrectly labeled (according to the strict semantic meaning of the class), and yet they are relatively similar (in terms of their acoustics) to the true label. We include some comments on this matter in the following Table.
| Class | comments on the content of Incorrect/OOV |
|---|---|
| Bass guitar | ≈ 2/3 of the clips are electronic baselines and bass drums |
| Clapping | ≈ 2/3 of the clips are applause sounds or electronic clap sounds generated by drum machines |
| Coin (dropping) | a bit more than half of the clips are coins not dropping, or syntethic coins dropping |
| Crash cymbal | ≈ half of the clips are not Crash cymbals but other type of cymbals |
| Dishes, pots, and pans | ≈ 1/4 of the clips are cutlery sounds |
| Piano | a bit more than half of the clips are not specifically pianos but keyboards or synthesizers |
| Tearing | almost 1/5 of the clips are velcro sounds or packing tape sounds |
| Wind | almost 1/5 of the clips are ventilators, fans or people blowing the mic |
FSDnoisy18k basic characteristics
The dataset most relevant characteristics are as follows:
- FSDnoisy18k contains 18,532 audio clips (42.5h) unequally distributed in the 20 aforementioned classes drawn from the AudioSet Ontology.
- The audio clips are provided as uncompressed PCM 16 bit, 44.1 kHz, mono audio files.
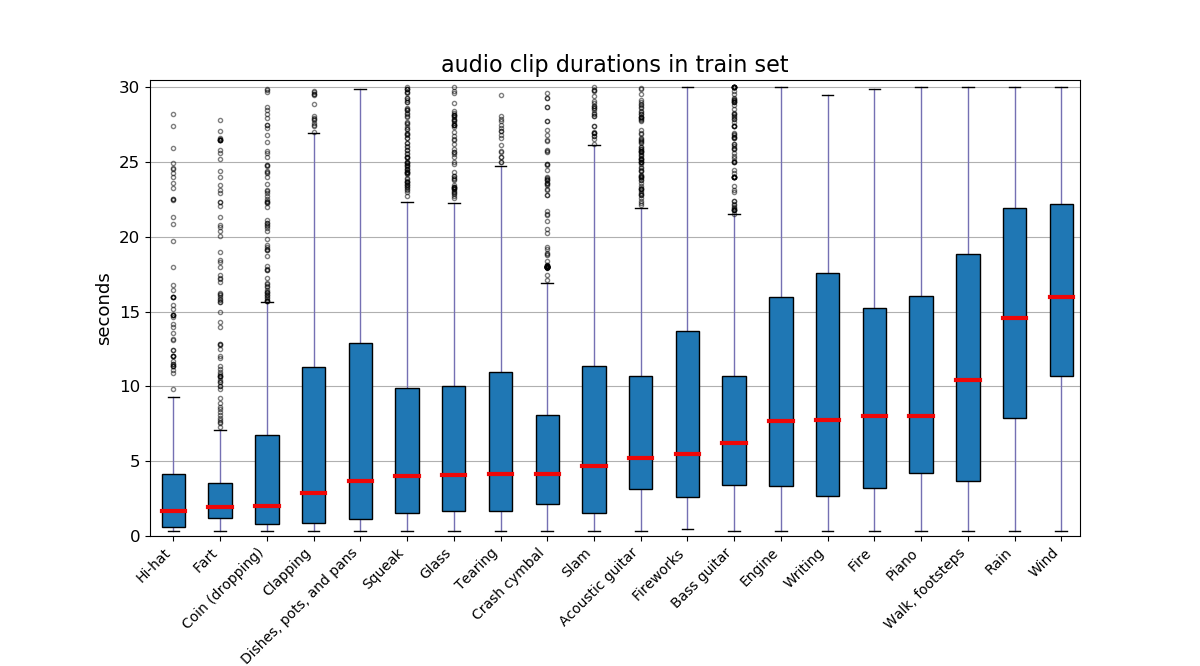
- The audio clips are of variable length ranging from 300ms to 30s, and each clip has a single ground truth label (singly-labeled data).
- The dataset is split into a test set and a train set as seen in Fig. 2. The test set is drawn entirely from the clean portion, while the remainder of data forms the train set.
- The train set is composed of 17,585 clips (41.1h) unequally distributed among the 20 classes. It features a clean subset and a noisy subset. In terms of number of clips their proportion is 10%/90%, whereas in terms of duration the proportion is slightly more extreme (6%/94%). The per-class percentage of clean data within the train set is also imbalanced, ranging from 6.1% to 22.4%. The number of audio clips per class ranges from 51 to 170, and from 250 to 1000 in the clean and noisy subsets, respectively. Further, a noisy small subset is defined (dark blue box in Fig. 2), which includes an amount of (noisy) data comparable (in terms of duration) to that of the clean subset.
- The test set is composed of 947 clips (1.4h) that belong to the clean portion of the data. Its class distribution is similar to that of the clean subset of the train set. The number of per-class audio clips in the test set ranges from 30 to 72. The test set enables a multi-class classification problem.
- FSDnoisy18k is an expandable dataset that features a per-class varying degree of types and amount of label noise. The dataset allows investigation of label noise as well as other approaches, from semi-supervised learning, e.g., self-training [8] to learning with minimal supervision [21].
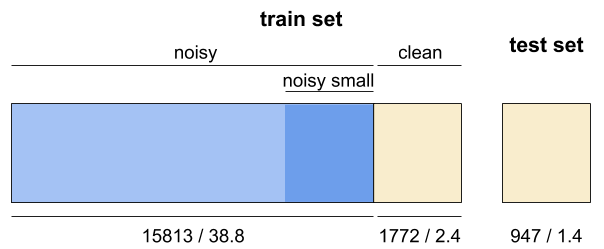 |
|---|
| Fig 2. Data split in FSDnoisy18k, including number of clips / duration in hours. Blue = noisy data. Yellow = clean data. |
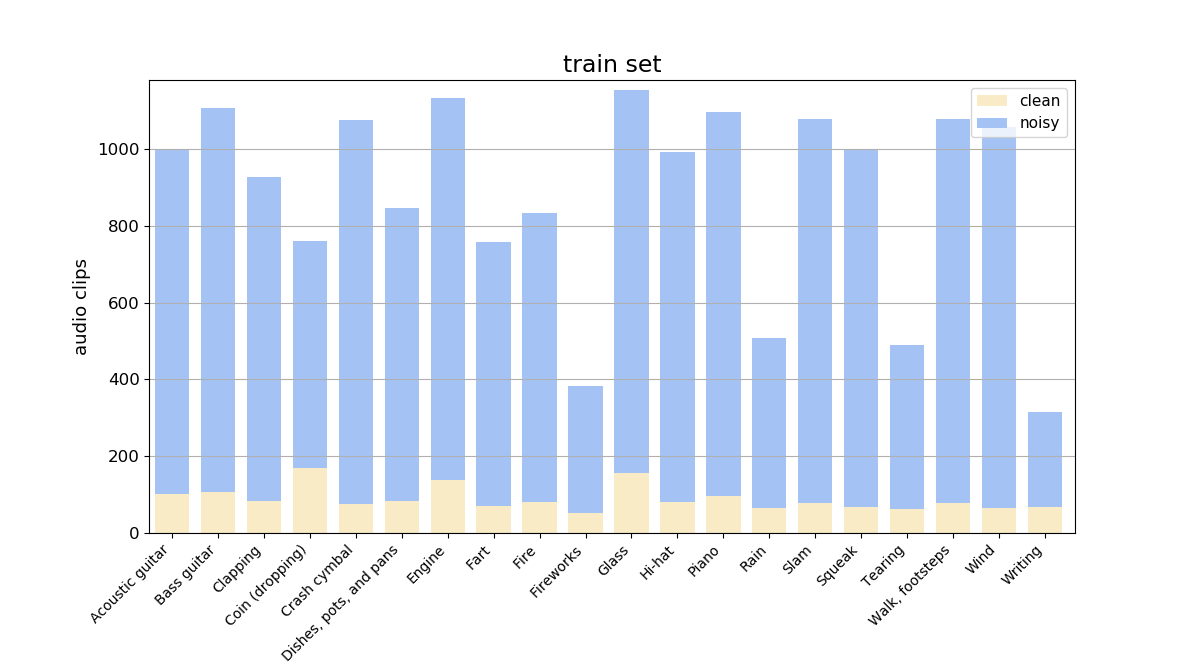
Figs. 3 and 4 illustrate the distribution of audio clips across the categories in the train set, and the diversity of audio clip durations across the categories in the train set, respectively.
 |
|---|
| Fig 3. Distribution of audio clips across the categories in the train set of FSDnoisy18k. Blue = noisy data. Yellow = clean data. |
 |
|---|
| Fig 4. Boxplot of audio clip durations across the categories in the train set of FSDnoisy18k. |
License
FSDnoisy18k has licenses at two different levels, as explained next.
All sounds in Freesound are released under Creative Commons (CC) licenses, and each audio clip has its own license as defined by the audio clip uploader in Freesound. In particular, all Freesound clips included in FSDnoisy18k are released under either CC-BY or CC0. For attribution purposes and to facilitate attribution of these files to third parties, we include a relation of audio clips and their corresponding license in the LICENSE-INDIVIDUAL-CLIPS file downloaded with the dataset (see Files section below).
In addition, FSDnoisy18k as a whole is the result of a curation process and it has an additional license. FSDnoisy18k is released under CC-BY. This license is specified in the LICENSE-DATASET file downloaded with the dataset (see Files section below).
Download
The dataset is available under the mentioned open licenses and can be downloaded from Zenodo on the following link, along with the proposed data splits for reproducibility:
https://doi.org/10.5281/zenodo.2529934
Files
FSDnoisy18k can be downloaded as a series of zip files with the following directory structure:
root
│
└───FSDnoisy18k.audio_train/ Audio clips in the train set
│
└───FSDnoisy18k.audio_test/ Audio clips in the test set
│
└───FSDnoisy18k.meta/ Files for evaluation setup
│ │
│ └───train.csv Data split and ground truth for the train set
│ │
│ └───test.csv Ground truth for the test set
│
└───FSDnoisy18k.doc/
│
└───README.md The dataset description file that you are reading
│
└───LICENSE-DATASET License of the FSDnoisy18k dataset as an entity
│
└───LICENSE-INDIVIDUAL-CLIPS.csv Licenses of the individual audio clips from Freesound
Each row (i.e. audio clip) of the train.csv file contains the following information:
fname: the file namelabel: the audio classification label (ground truth)aso_id: the id of the corresponding category as per the AudioSet Ontologymanually_verified: Boolean (1 or 0) flag to indicate whether the clip belongs to the clean portion (1), or to the noisy portion (0) of the train setnoisy_small: Boolean (1 or 0) flag to indicate whether the clip belongs to the noisy_small portion (1) of the train set
Each row (i.e. audio clip) of the test.csv file contains the following information:
fname: the file namelabel: the audio classification label (ground truth)aso_id: the id of the corresponding category as per the AudioSet Ontology
References and links
*For consistency, citations in this website have been kept with the same reference number as in our preprint.
[8] Benjamin Elizalde, Ankit Shah, Siddharth Dalmia, Min Hun Lee, Rohan Badlani, Anurag Kumar, Bhiksha Raj, and Ian Lane, “An approach for self-training audio event detectors using web data,” in Signal Processing Conference (EUSIPCO), 2017 25th European. IEEE, 2017, pp. 1863–1867.
[10] Ankit Shah, Anurag Kumar, Alexander G Hauptmann, and Bhiksha Raj, “A closer look at weak label learning for audio events,” arXiv preprint arXiv:1804.09288, 2018
[14] Frederic Font, Gerard Roma, and Xavier Serra, “Freesound technical demo,” in Proceedings of the ACM International Conference on Multimedia. ACM, 2013, pp. 411–412.
[15] Eduardo Fonseca, Jordi Pons, Xavier Favory, Frederic Font, Dmitry Bogdanov, Andre ́s Ferraro, Sergio Oramas, Alastair Porter, and Xavier Serra, “Freesound datasets: a platform for the creation of open audio datasets,” in Proceedings of the 18th International Society for Music Information Retrieval Confer- ence (ISMIR 2017), Suzhou, China, 2017, pp. 486–493.
[20] Veronica Morfi and Dan Stowell, “Data-efficient weakly supervised learning for low-resource audio event detection using deep learning,” arXiv preprint arXiv:1807.06972, 2018.
[21] Andreas Veit, Neil Alldrin, Gal Chechik, Ivan Krasin, Abhinav Gupta, and Serge J Belongie, “Learning from noisy large-scale datasets with minimal supervision.,” in CVPR, 2017, pp. 6575– 6583.
Source code for our preprint: https://github.com/edufonseca/icassp19
Freesound Annotator: https://annotator.freesound.org/
Freesound: https://freesound.org
Eduardo Fonseca’s personal website: http://www.eduardofonseca.net/
Acknowledgments
This work is partially supported by the European Union’s Horizon 2020 research and innovation programme under grant agreement No 688382 AudioCommons. Eduardo Fonseca is also sponsored by a Google Faculty Research Award 2017. We thank everyone who contributed to FSDnoisy18k with annotations.