
Happy to announce that the paper from my 2nd internship at Google Research received the “Best Audio Representation Learning Paper Award” at WASPAA 2021!!
E. Fonseca, A. Jansen, D. P. W. Ellis, S. Wisdom, M. Tagliasacchi, J. R. Hershey, M. Plakal, S. Hershey, R. C. Moore, X. Serra.
Self-Supervised Learning from Automatically Separated Sound Scenes
IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New York, USA, 2021
[PDF]
[slides]
[video]
We’re honored to receive this Award at one of the most relevant conferences in the field of audio processing, which was held last month online. The paper explores the use of automatic sound separation to decompose sound scenes into multiple semantically-linked views for use in self-supervised representation learning.
This work is a collaboration with multiple researchers at Google Research from New York, California, Massachusetts and Switzerland. We’re all very grateful to WASPAA organizers. And I am super grateful to all the co-authors of this work, and especially to Aren Jansen and Dan Ellis for a great supervision and support.
A peek into the paper
Real-world sound scenes consist of time-varying collections of sound sources, each generating characteristic sound events that are mixed together in audio recordings. The association of these constituent sound events with their mixture and each other is semantically constrained: the sound scene contains the union of source classes and not all classes co-occur naturally. With this motivation, the paper explores the use of automatic sound separation to decompose sound scenes into multiple semantically-linked views for use in self-supervised contrastive learning.
The figure illustrates the proposed system.
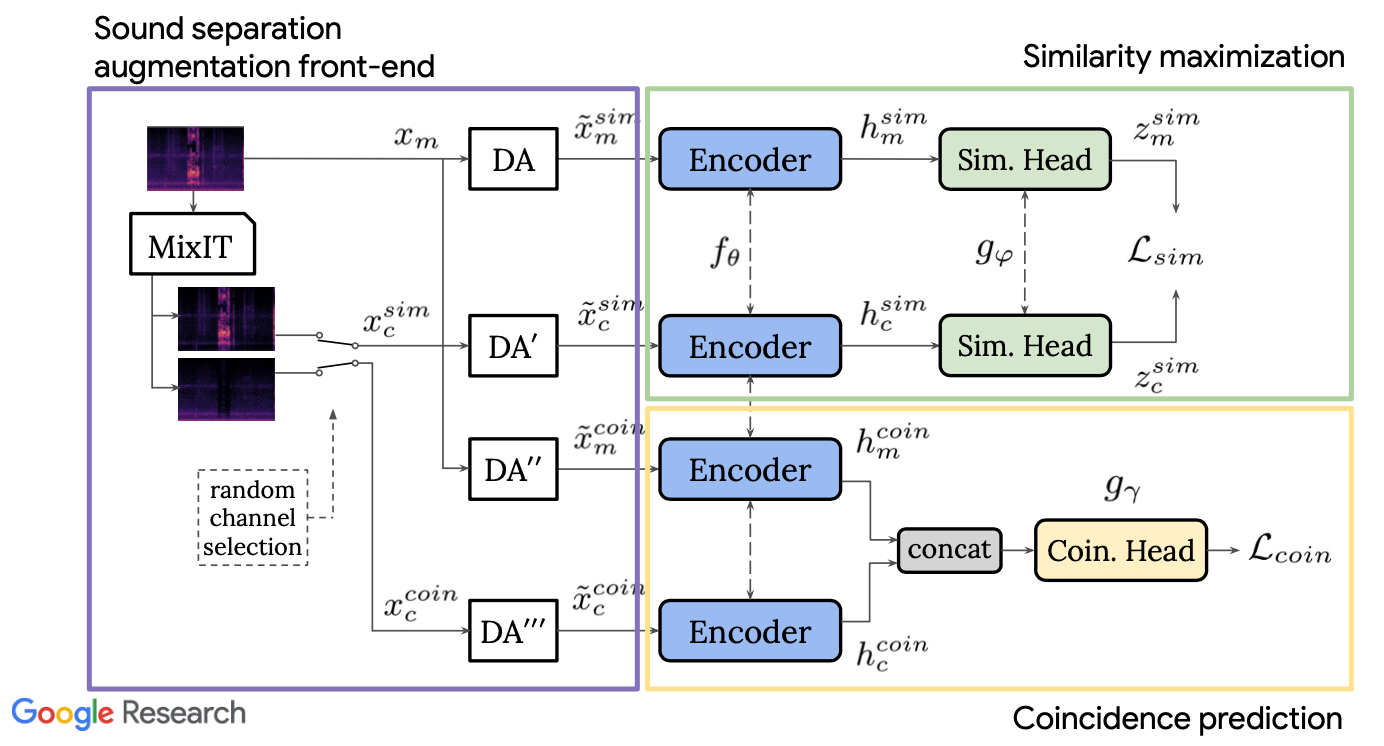
We show that sound separation can be seen as a valid augmentation to generate positive views for contrastive learning. In particular, learning to associate input sound mixtures with their constituent separated channels elicits semantic structure in the learned representation, outperforming comparable systems without separation. Through extensive experimentation, we also discover that optimal sound separation performance is not essential for successful representation learning.
An extended version of the WASPAA 2021 submission with additional discussion for easier consumption is available on arXiv. A video presentation as well as the slide deck used are also available (see top of the page).
Please check our paper for more details! Hope to keep exploring more self-supervised mechanisms in the future.