
This post overviews the paper:
E. Fonseca, D. Ortego, K. McGuinness, N.E. O’Connor, X. Serra.
Unsupervised Contrastive Learning of Sound Event Representations
IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2021
[PDF]
[code]
[slides]
[poster]
[video]
In the past years, we’ve witnessed important advances in unsupervised learning, first in computer vision and then in the speech community. The next step is learning representations of sound events or general-purpose audio. This makes a lot of sense given the abundant sources of audio data available. Websites such as Freesound or Flickr host substantial amounts of open-licensed audio(visual) material with high diversity of everyday sounds. Self-supervised learning mechanisms allow leveraging this unlabeled audio content in order to learn useful audio representations without prior manual labelling.
Proposed method
Our proposed method is inspired by the seminal work on visual representation learning SimCLR [1]. The method consists of learning a representation by comparing differently augmented versions (or views) of the same input example. There, the authors deal with images, while here we use audio spectrograms. One of the key factors is how the different views are generated in order to determine a challenging (but suitable) proxy learning task. By solving this task, the goal is to obtain discriminative representations.
In SimCLR, some computer vision oriented augmentations are used (like random crop or color distortion). One of the contributions of our work is to find suitable transformations to generate different views for our task with audio spectrograms. The figure illustrates the proposed system.
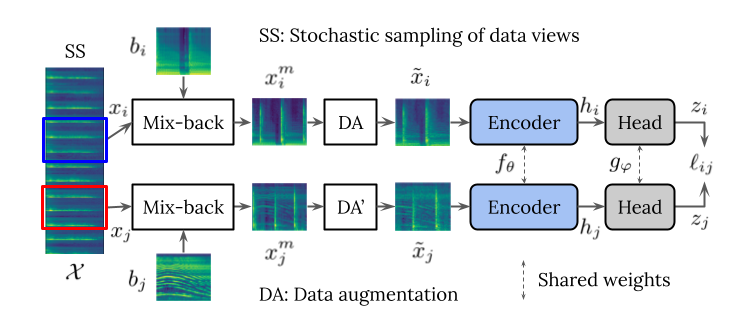
These transformations are as follows:
- sampling Time-Frequency patches at random within every input clip,
- mixing resulting patches with unrelated background clips (mix-back), and
- other data augmentations (DAs) like RRC, compression, noise addition or SpecAugment [2].
After computing the different views, we use a CNN to extract low dimensional representations that are ultimately compared with a contrastive loss. Essentially, by minimizing this loss we do two things. On the one hand, we maximize the agreement between pairs of positive examples (like the ones in the figure, coming from the same initial example). On the other hand, we minimize the agreement between pairs of negative examples (constructed by pairing unrelated examples, e.g., one of those in the figure and anoher random clip). This way, we pull together the representations of positive examples in the embedding space, while pushing apart the representations of the negative ones.
If the example views are appropriate, this training task will produce a semantically structured embedding space. Then we will use the learned embeddings for downstream sound event classification tasks. This is especially useful for the cases when only few data, or poorly labeled data, are available.
Experimental setup
The setup that we follow consists of two stages:
-
Unsupervised contrastive representation learning by comparing differently augmented views of sound events. The outcome of this stage is a trained encoder to produce low-dimensional representations.
-
Evaluation of the representation using a previously trained encoder in supervised learning tasks. We follow two evaluation methods:
- linear evaluation, in which we train an additional linear classifier on top of the pre-trained unsupervised embeddings, and
- end-to-end fine tuning, where we fine-tune the entire model on two downstream tasks after initializing with pre-trained weights.
For all these stages we use the FSDnoisy18k dataset [3], which contains 42.5h of Freesound audio distributed across 20 classes. In particular, the dataset includes a small clean training set (2.4h), and a larger train set with noisy labels (38.8h). Therefore, this dataset allows us to do fine tuning on two downstream tasks that are relevant for sound event research: training on a larger set of noisy labels and training on a much smaller set of clean data. We use three models in our experiments: ResNet-18, VGG and CRNN.
Insights from ablation study
We run ablation studies to understand the impact of each block of the figure in unsupervised learning. You can check our paper for the details, but the main takeaways are:
- Using exactly the same initial patch from where to obtain the views is not great. We found that selecting two patches at random from each clip is the way to go. In particular, we found out that selecting them randomly outperforms separating them deterministically.
- Mixing examples with other examples is important. We saw that it was beneficial to mix them with patches from other random clips (instead of from the same clip).
- Data augmentations are also important, and they don’t need to be complex or mathematically rigorous from the acoustic perspective. Simple transformations for on-the-fly processing are valid.
- We used random resized cropping, with a bit of compression and noise addition. We also found SpecAugment useful. We believe better compositions than the ones we came up with in the paper are possible.
So what is the key ingredient? We found that there is not one single key ingredient here, but rather it is the composition of the transformations above what makes the proxy task effective. The solution is not to add many transformations, just a few of the right ones, and in a proportionate manner.
Insights from evaluating the learned representation
Once a sound event representation was learned in unsupervised fashion, we evaluated this representation following the two mentioned evaluation approaches. The main takeaways are:
In linear evaluation, ResNet-18 is the top performing system, exceeding a supervised baseline trained from scratch. This suggests that the larger capacity of a ResNet-18 (compared to other models used) is better for unsupervised contrastive learning. For VGG and CRNN, most of the supervised performance is recovered.
By fine tuning the pretrained models on downstream tasks, we aim to measure the benefits with respect to training from scratch in both noisy- and small-data regimes. Interestingly, we found out that unsupervised contrastive pre-training is best in all cases! Specifically, ResNet-18 attains the lowest accuracy when trained from scratch (presumably limited by the amount of data or the label quality in the noisy set of FSDnoisy18k). In contrast, this architecture yields top accuracy when initialized with pre-trained weights, suggesting that unsupervised pre-training can alleviate these problems to some extent.
Overall, the results are pretty interesting as they show the potential of larger capacity networks like ResNet for unsupervised contrastive learning, while they don’t especially shine when used for supervised classification with this amount of data (few tens of hours of audio), at least with Freesound audio. Whether these promising results hold when increasing training data to hundreds or thousands of hours is a question to be answered in future work.
Final thoughts
We’ve shown that it is possible to learn effective representations by tuning the compound of positive patch sampling & mix-back & data augmentation. Our results suggest that unsupervised contrastive pre-training can mitigate the impact of data scarcity and increase robustness against noisy labels.
What’s very cool about this framework is its simplicity and how intuitive it is compared to other proxy tasks in the self-supervised literature. Also, despite the simplicity, it works pretty well in our paper and also in other recent papers. Perhaps, what’s not that cool is that we found it to be relatively sensitive to parameter changes, e.g., in the augmentations or other parameters in the pipeline like the loss’ temperature.
Hope to explore more self-supervised mechanisms and proxy tasks in the future. It’s actually quite fun.
Wanna learn more? Please check our paper for more details!
E. Fonseca, D. Ortego, K. McGuinness, N.E. O’Connor, X. Serra.
Unsupervised Contrastive Learning of Sound Event Representations
IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2021
[PDF]
[code]
[slides]
[poster]
[video]
Thanks!
This work is a collaboration between the MTG-UPF and Dublin City University’s Insight Centre. It’s been a pleasure to work together, especially working closely with Diego Ortego. This work is partially supported by Science Foundation Ireland (SFI) under grant number SFI/15/SIRG/3283 and by the Young European Research University Network under a 2020 mobility award. Eduardo Fonseca is partially supported by a Google Faculty Research Award 2018. The authors are grateful for the GPUs donated by NVIDIA.
References
[1] T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A Simple Framework for Contrastive Learning of Visual Representations,” in Int. Conf. on Mach. Learn. (ICML), 2020
[2] Park et al., SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition. InterSpeech 2019
[3] E. Fonseca, M. Plakal, D. P. W. Ellis, F. Font, X. Favory, X. Serra, “Learning Sound Event Classifiers from Web Audio with Noisy Labels”, In proceedings of ICASSP 2019, Brighton, UK